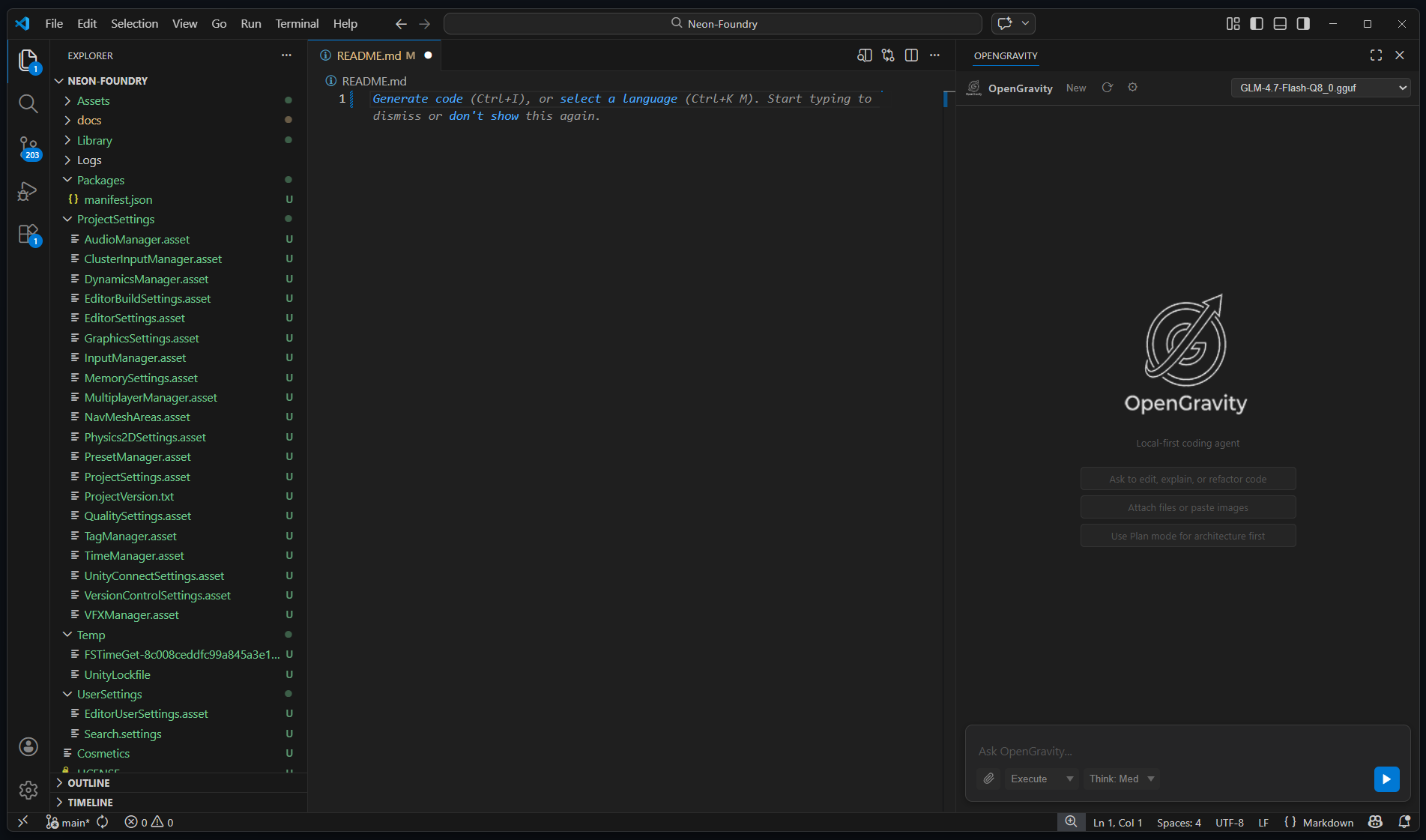
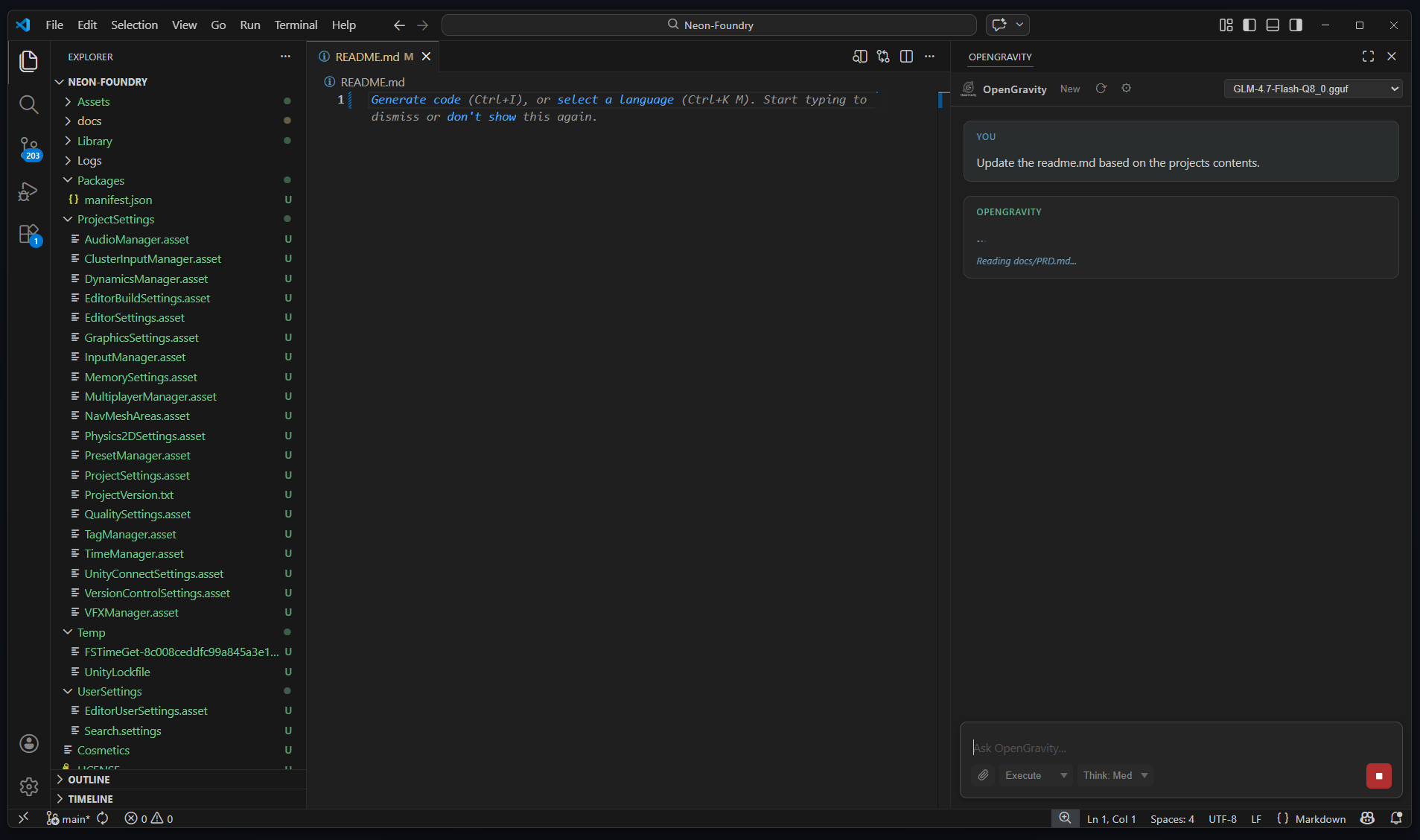
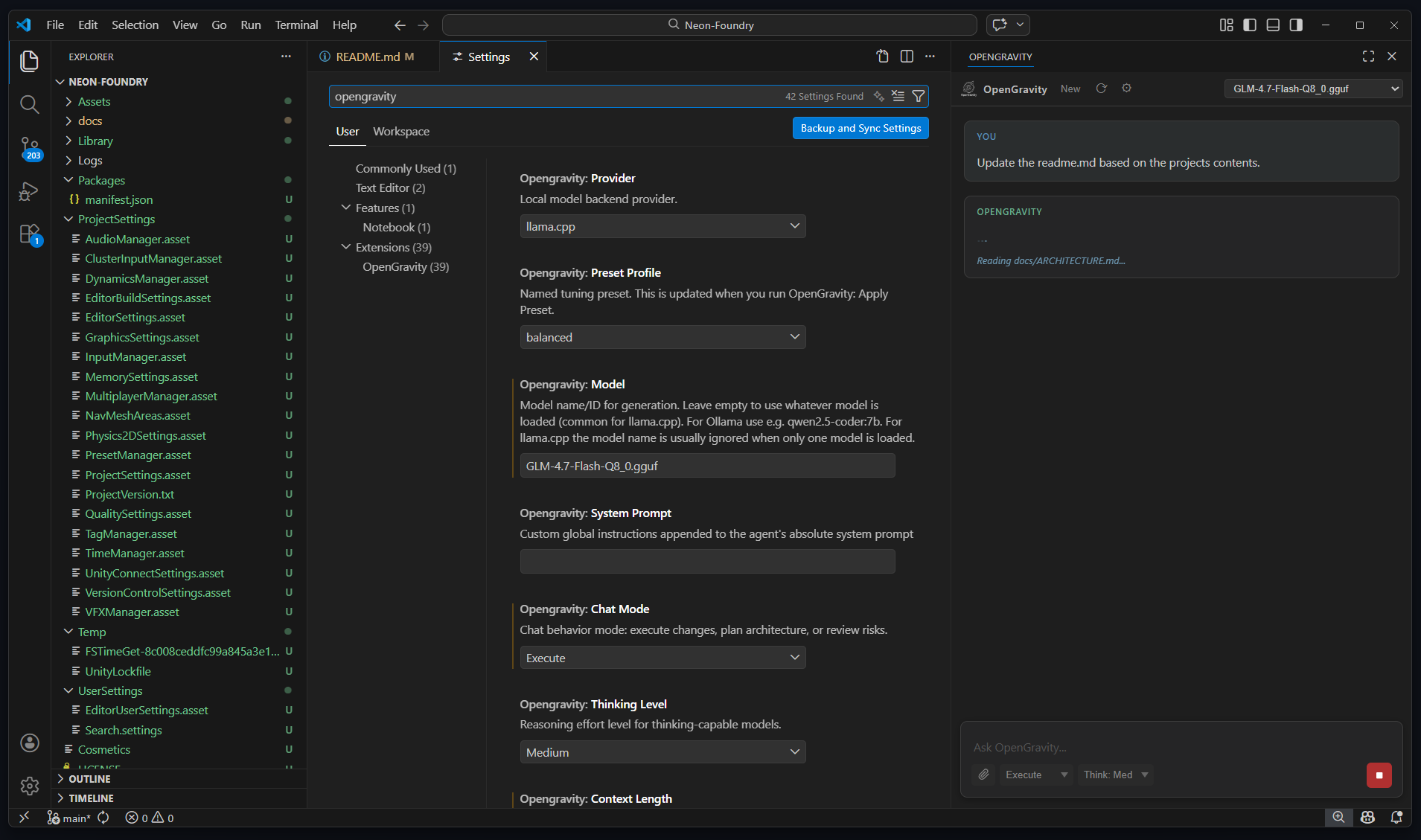
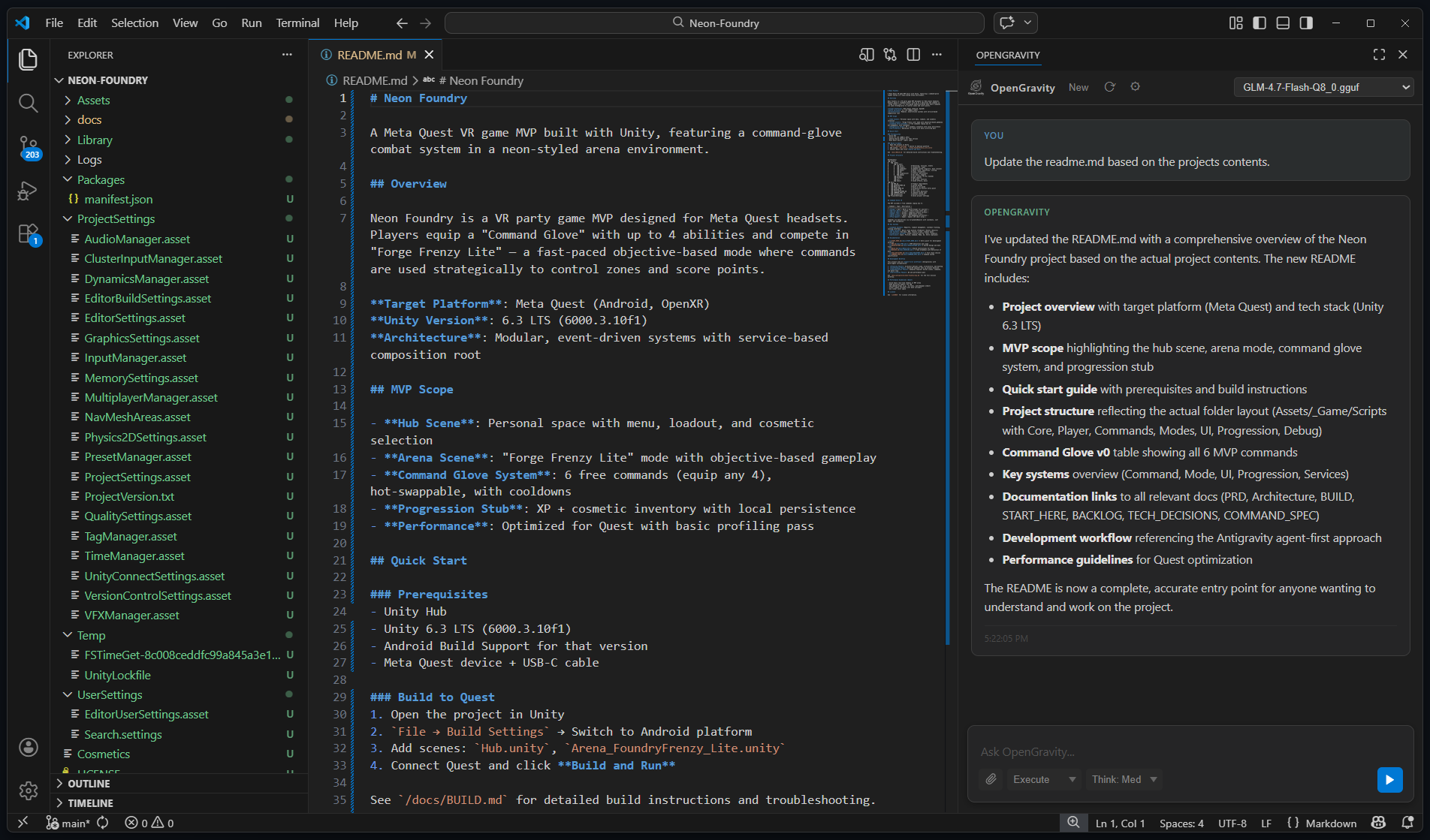
Built for serious development work — not demos.
🤖
Autonomous Agent
Reads files, searches code, writes changes, and executes multi-step tasks without hand-holding. Up to 40 tool-call steps per request.
🔒
Total Privacy
Zero data ever leaves your machine. No telemetry, no API keys, no cloud inference. Works fully offline on your own hardware.
⚡
Streaming Responses
Tokens stream to the screen as they're generated. See the agent's thinking in real time — no more waiting for a full response.
🌐
Web Search & Fetch
Search the web via Brave Search or self-hosted SearXNG, then fetch pages for full context. Docs, specs, GitHub files — all fair game.
📋
Session Continuity
Automatically writes PLAN.md at the end of every task. On the next session the agent reads it first — no context lost between conversations.
✏️
Inline Autocomplete
Ghost-text completions as you type using your local model. Supports Fill-in-the-Middle (FIM) for Qwen, DeepSeek-Coder, CodeLlama, and StarCoder.
🔍
Smart Context
Active editor gets priority budget. VS Code diagnostics, git branch, recent commits, and uncommitted diffs are injected automatically.
🗂️
Persistent History
Chat history survives VS Code restarts. When conversations grow large, older turns are automatically summarized to stay within context limits.
🖥️
Remote GPU Support
Run llama.cpp on a powerful desktop or server and connect from any laptop. Up to 128K context (configurable) over the network with a single URL change.